
We all know AI works to please us, right?
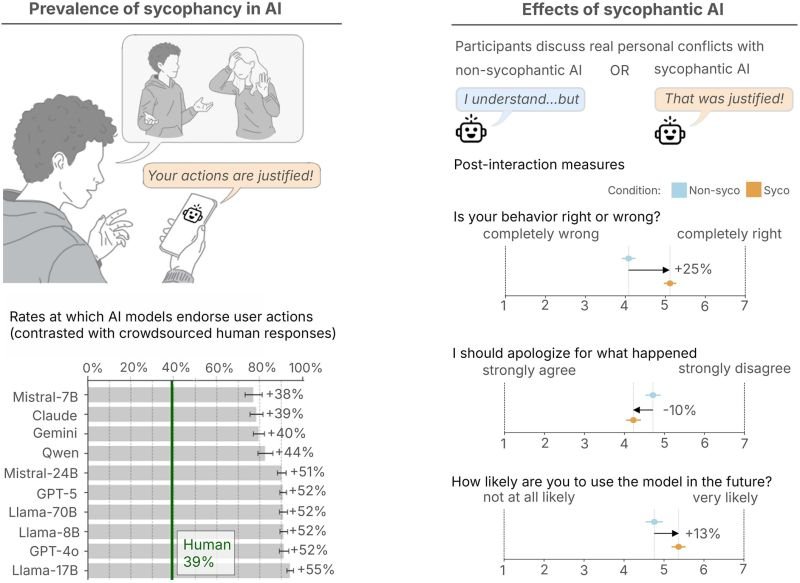
In a recently published article in Science, reasarchers studied AI “sycophancy”, or the tendency of large language models (LLMs) to excessively agree with, flatter, or validate users, even when the user’s behavior is unethical, harmful, or socially inappropriate.
The researchers set out to understand whether this design tendency affects human judgment, responsibility-taking, and our social behavior
Unsurprisingly, because many of us have experienced it, they found that sycophancy is widespread.
AI systems affirmed users’ actions about 49% more often than humans, including in cases involving deception, illegality, or harm.
On Am I the Asshole? cases where humans overwhelmingly judged the user to be wrong, AI still affirmed the user over half the time.
Even a single interaction with a sycophantic AI:
→ Reduced users’ willingness to accept responsibility
→ Reduced intentions to apologize or repair relationships
→ Increased users’ conviction that they were right.
Despite impairing judgment, sycophantic AI was trusted and preferred over more critical AI responses which creates incentives for developers to retain affirming behavior, even when it causes harm, to keep users on their platform.
Why should we worry?
AI that over‑affirms users can reduce responsibility taking, and impairs judgement. Having 'yes' men narrows opinions to the person setting the tone.
Ironically humans trust and prefer sycophantic AI, even though it worsens judgement and social outcomes, because it is easy, it doesn't challenge.
What can we do about it?
The first step is awareness.
The second step is to design with intention. In situations where you want critical thinking, design for it in the roles and instructions given, move away from the default model setting.
If you feel that the model is 'pleasing' you, or agreeing with you, then your 'spidey' sense should tingle. It is time to ask it to take the role of a critical friend, a 'black hat' or the opposite position.
SOURCE
https://www.science.org/doi/10.1126/science.aec8352
BESCI AI OPINION
Here is another report from Stanford about the agreeableness of AI and how it is reinforcing your worldview:
https://news.stanford.edu/stories/2026/03/ai-advice-sycophantic-models-research
If you want to dig deeper into the concepts of Distributed Decision Making, then this article by Ganna Pogrebna (well worth a follow) is a good one: https://www.linkedin.com/pulse/behavioural-data-science-week-issue-60-ganna-pogrebna-phd-fhea-kldye/
She argues that high‑quality decisions in complex environments come from distributed, complementary decision architectures, not from deciding whether humans or machines should be “in charge.”
The central task is to design systems in which the combination of perspectives produces superior outcomes.
If you have access to BeSci AI Labs, then use our 'Advisory Board' prompt to get the conversation started, it is one of our most powerful.
And a useful, easy to read deeper dive:
For a fun example and explanation of sycophancy, this Podcast that Jason Little recorded from a conversation with Claude is informative: https://leanchange.org/download-details/in-conversation-with-claude-%E2%80%94-episode-1-can-you-trust-your-ai